
Tutorial
Index
Setup summary
Here's a tutorial to help you set up the Data Scraping Crawler:
Give the URLs of the web pages you're interested in
You have two options:
1. Process a single website
Enter your URL directly into the Phantom's setup.2. Process multiple websites
Create a spreadsheet with Google Sheets. Copy the website URLs and paste them into your spreadsheet - one URL per row, all in column A.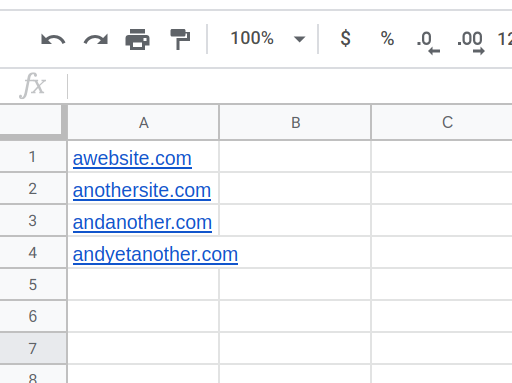
Make this spreadsheet public so PhantomBuster can access it.
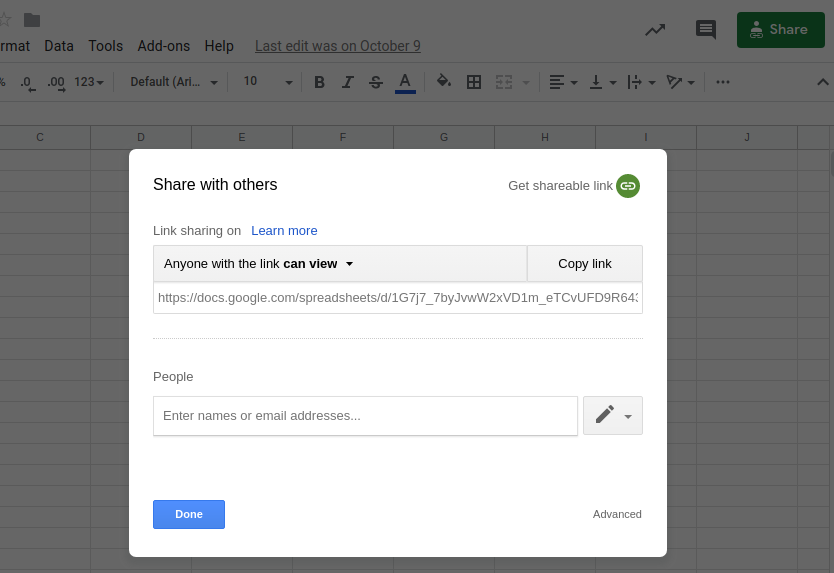
Copy the spreadsheet URL and paste it into your Phantom's setup.
Specify which contact and social media data you want to scrape
Select which of the data below you would like to scrape from each website by checking the boxes of each one you want:
Email addresses
Phone numbers
Facebook page URLs
Instagram profile URLs
Twitter profile URLs
LinkedIn company page URLs
YouTube channel URLs
Pick the condition under which the Phantom should exit a website
When you really start digging into a website, you'll realize you can dig very far and even get lost in the vast depths of some. To stop your Phantom continuously digging and getting stuck on one site, you'll need to choose a condition under which it will stop its scrape and exit the site. This will save your execution time and ensure all your websites get processed.
Depending on what you want, you can choose from the following options:
Website depth
This refers to the number of layers of a site the Phantom will visit before exiting, collecting any relevant data it finds along the way.
For example, setting a depth of 0 means that the Phantom will visit the URL you've given and go no further, while a depth of 1 means it will also visit every link on that page, and a depth of 2 every link on those pages, and so on.
Take note: Setting a depth of 2 or more is not recommended, as it means your Phantom will likely take a very long time to run.
When an email address is found
The Phantom will exit after having found an email address.
When a phone number is found
The Phantom will exit after having found a phone number.
When a social network is found
The Phantom will exit after having found any social media page.
After having opened X pages
The Phantom will exit after having opened the defined number of subpages on the site.
Define advanced settings
Scrape multiple results per website
Check this box if you want to extract not only the first but every available instance of the data you're scraping on all the pages you're browsing.Only visit web pages that start with a particular root URL
This option is useful if you only want to visit specific pages within a website.
For example, if scraping the PhantomBuster website, you could use https://phantombuster.com/phantombuster?category=linkedinhttps://phantombuster.com/automations/linkedin/3149/linkedin-search-export


