
Tutorial
Index
Give the URLs of the web pages you're interested in
You have two options:
1. Process a single web page
Enter your URL directly into the Phantom's setup. Then, set up one selector for each element you want to extract.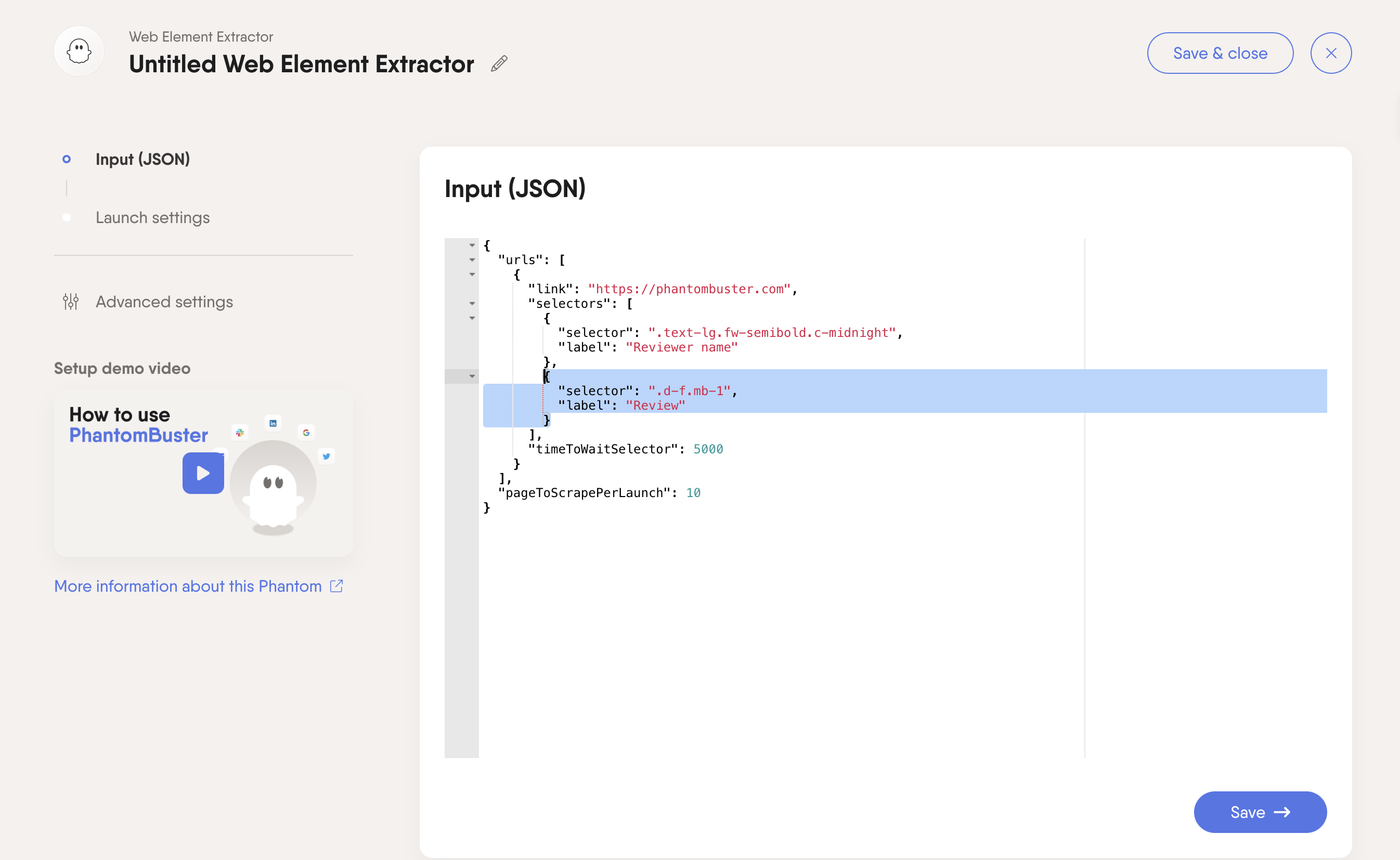
2. Process multiple web pages
Create a spreadsheet with Google Sheets. Copy the web page URLs and paste them into your spreadsheet - one URL per row, all in column A.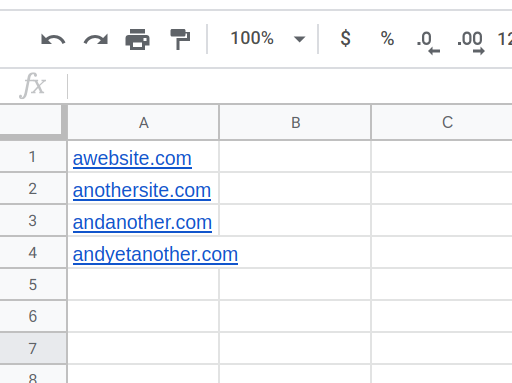
Make this spreadsheet public, so PhantomBuster can access it.
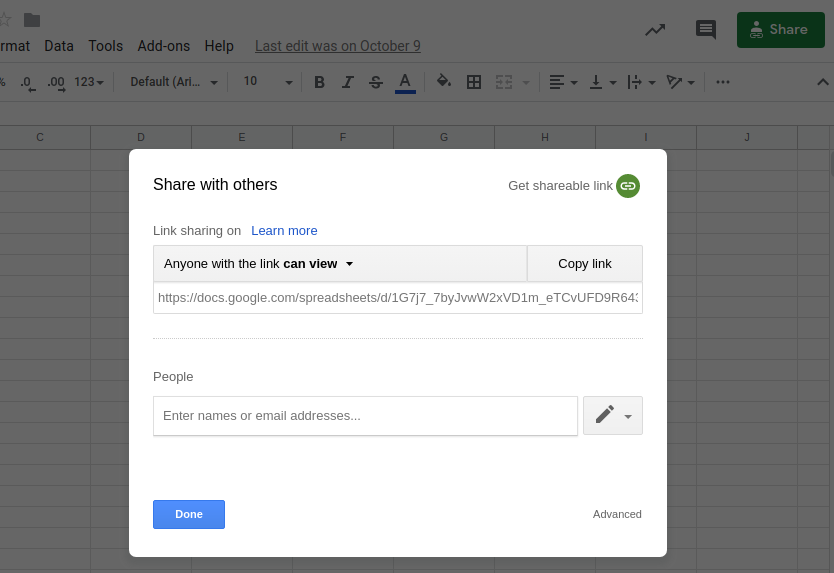
Copy the spreadsheet URL and paste it into your Phantom's setup.
Identify the web elements you want to scrape using CSS selectors
CSS selectors are the best way to precisely select any region or specific element of a web page. You can find the CSS selector of the web element you're interested in within the code of the page you're scraping.
For example, say you want to extract all the recipe names from a specific page on a recipe site. Here's how to find the CSS selector for the recipe name element:
Right-click anywhere on the page and select Inspect. This will open the Developer tools on the right side of the browser.
To make sure you've got the correct selector, click on the arrow in the top left of the Developer Tools window.
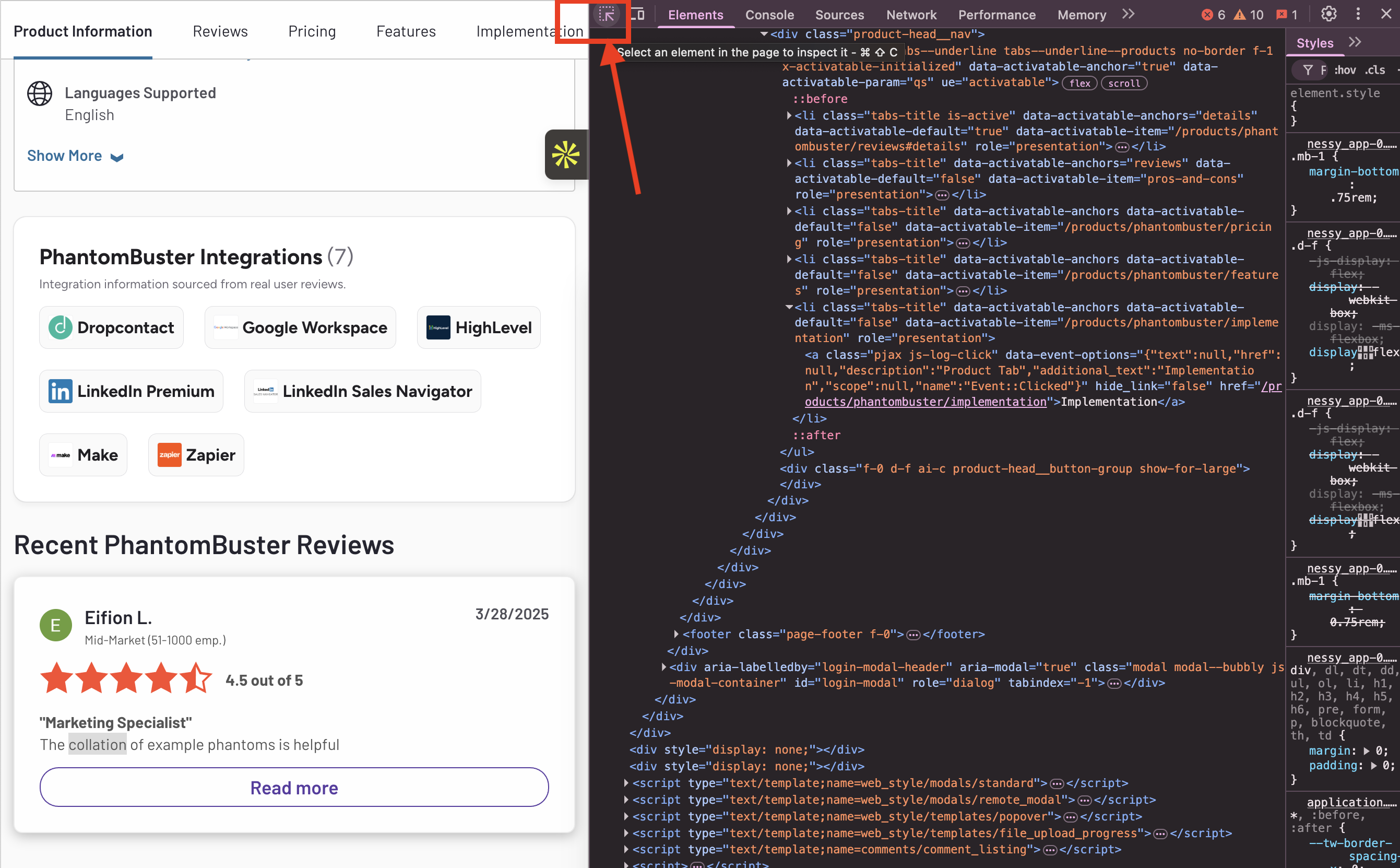
Hover over the element you're interested in and find the CSS selector at the top of the pop-up window, or click on the component and find it highlighted in the Elements tab of the Developer Tools window - e.g.
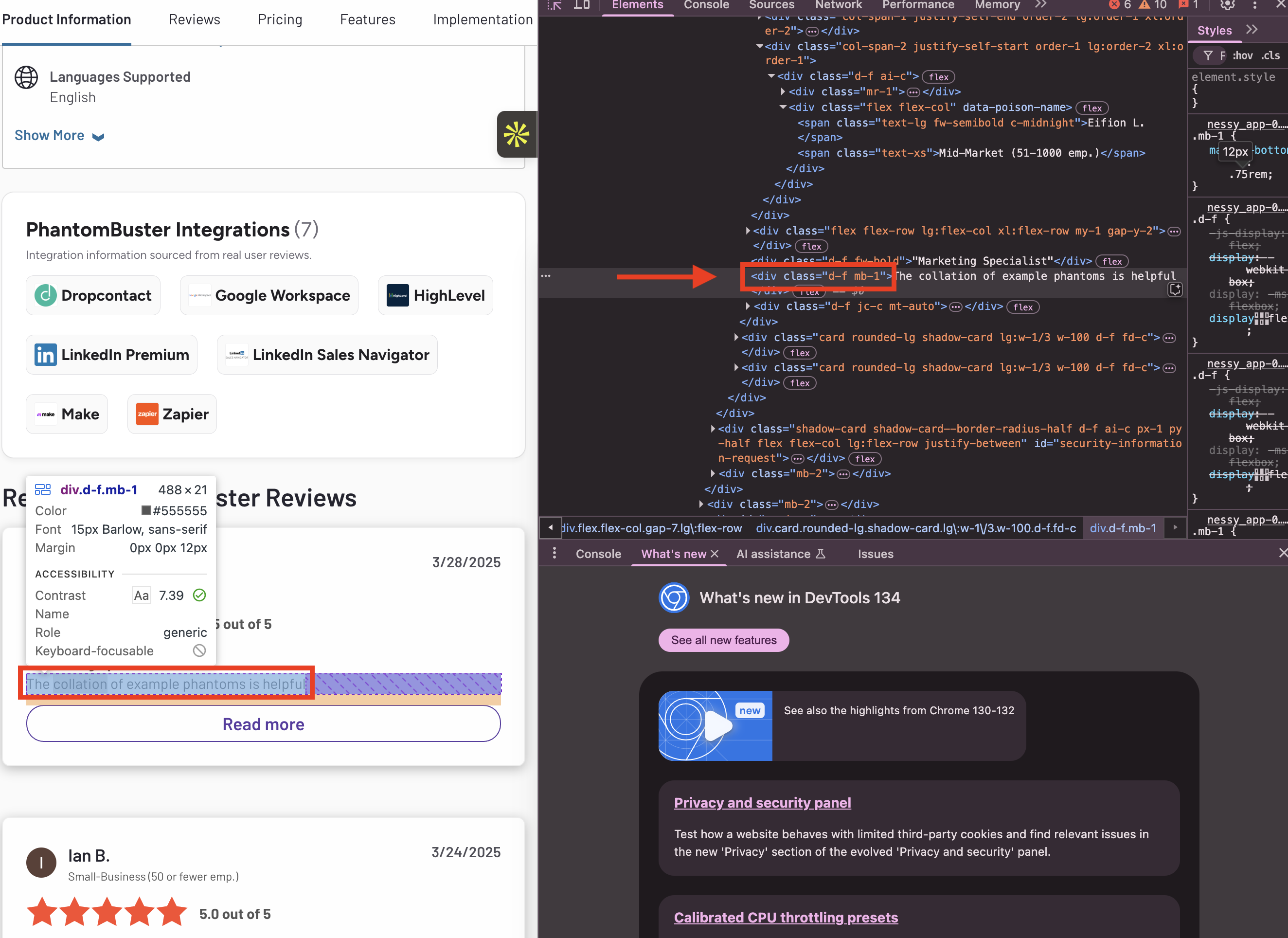
Copy the selector and paste it into the Phantom's setup
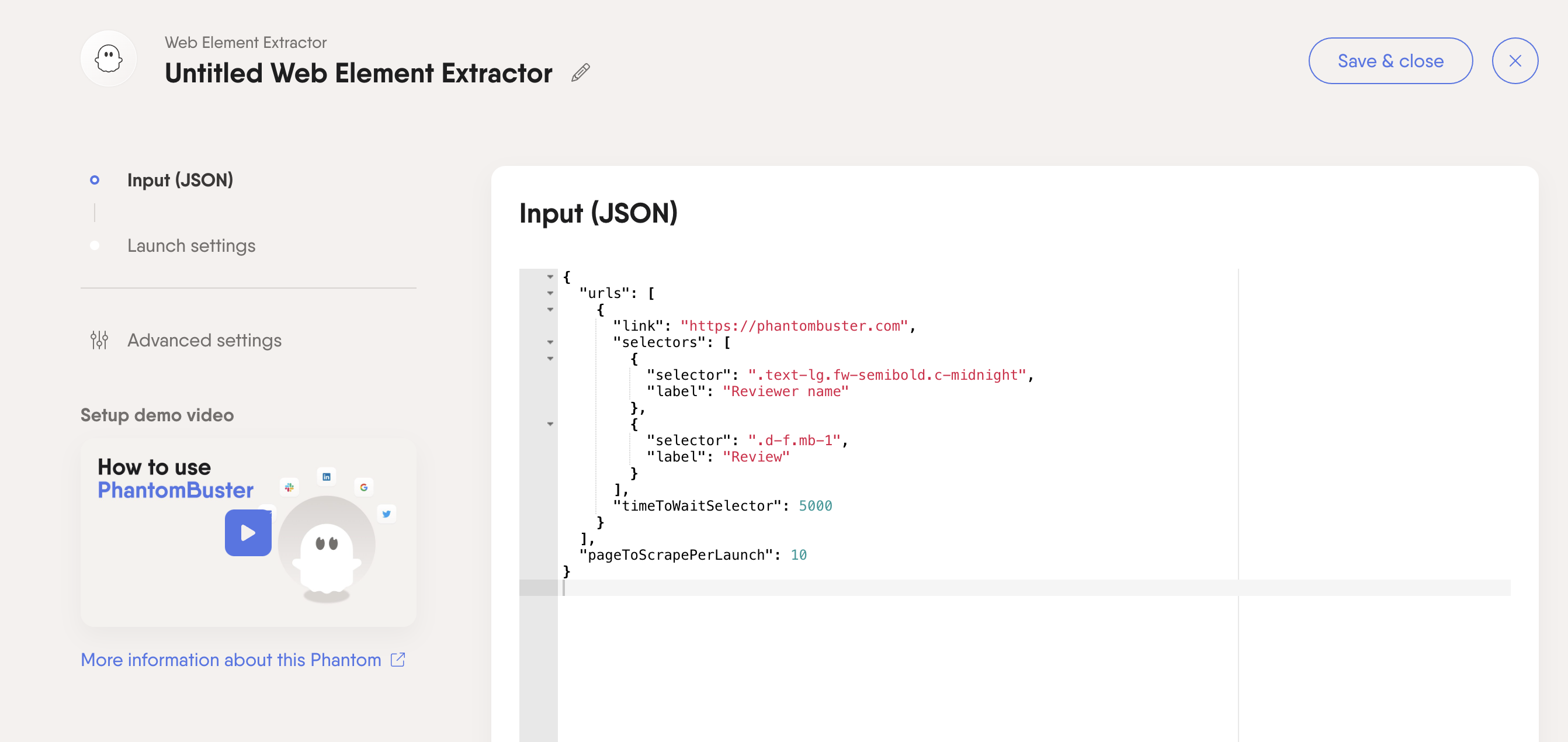
The Phantom will now extract all instances of the element identified by this CSS selector. You can add a label to the web element you're extracting so that it is easily identifiable in your results file.
To extract additional elements from the page, copy the selector and label text and add as many selectors as you need, separated by a comma.
{
"selector": ".add selector here",
"label": "add label here"
}






